I’ve been continuing to read a lot about generative AI and large language models. Each day seems to bring new announcements. This remains exciting, and gives a LOT of food for thought.
Yet beyond the excitement, I’m keen to seek out how this technology is being used, and its challenges. This month I wanted to share articles that focus on the practicalities of utilising LLMs.
All the Hard Stuff Nobody Talks About when Building Products with LLMs
“All the Hard Stuff Nobody Talks About when Building Products with LLMs” by Phillip Carter at Honeycomb was a decent, broad overview of some of the considerations and issues faced when building LLM-based features. I’d recommend this article to anyone planning and implementing these kinds of features into their product to gain an idea of the various challenges. A concise summary at the end of the article describes it well:
There are no right answers here. Just a lot of work, users who will blow your mind with ways they break what you built, and a whole host of brand new problems that state-of-the-art machine learning gave you because you decided to use it.
The article discusses the process of implementing a query assistant feature that can take a natural language input that describes a query, and output a valid Honeycomb query. I imagine a good analogy would be a query assistant for SQL, where you input “get me all the bookings” and the output is SELECT * FROM bookings.
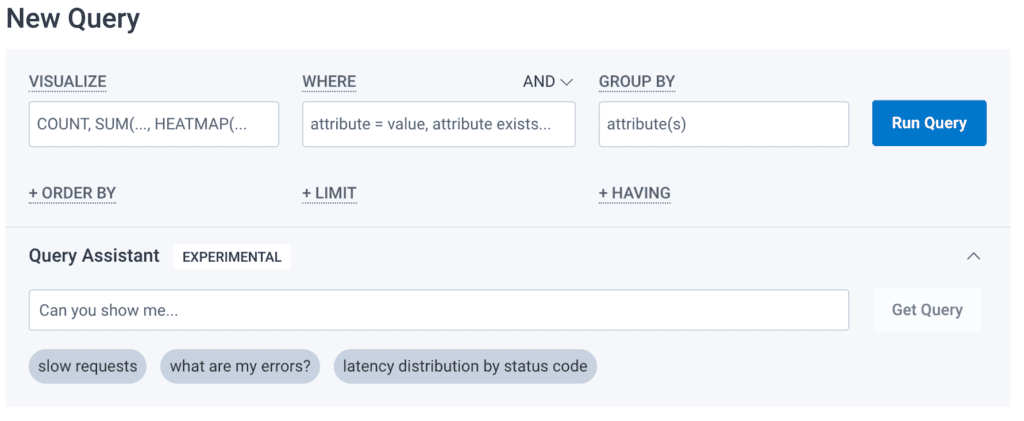
Specifically, the article has a really interesting discussion of the problem of context windows. Context windows are the range of tokens considered by a large language model, with the implied promise being that the larger the context window, the more information the model has to work with. A small context window may only allow for a few paragraphs of text, whereas a large one might allow for a whole book. Honeycomb faced issues with context window sizes when trying to include all the fields that a query might make use of. Some considerations were streamlining the context (at risk of leaving out important information), including only the relevant context via retrieval with embeddings (at risk of the retrieval being inaccurate), and using a larger context window, like Claude 100k (at risk of higher latency).
Harnessing Retrieval Augmented Generation With Langchain
I enjoyed reading “Harnessing Retrieval Augmented Generation With Langchain” by Amogh Agastya this month. The article is an extensive overview of Retrieval Augmented Generation (RAG). In summary, RAG is a method used with LLM’s to retrieve some additional information related to the user’s input and use that information as part of the prompt. This is the method that powers services like Perplexity AI. RAG is actually a potential solution to the issue of context window size if done right, as highlighted in the Honeycomb article shared above.
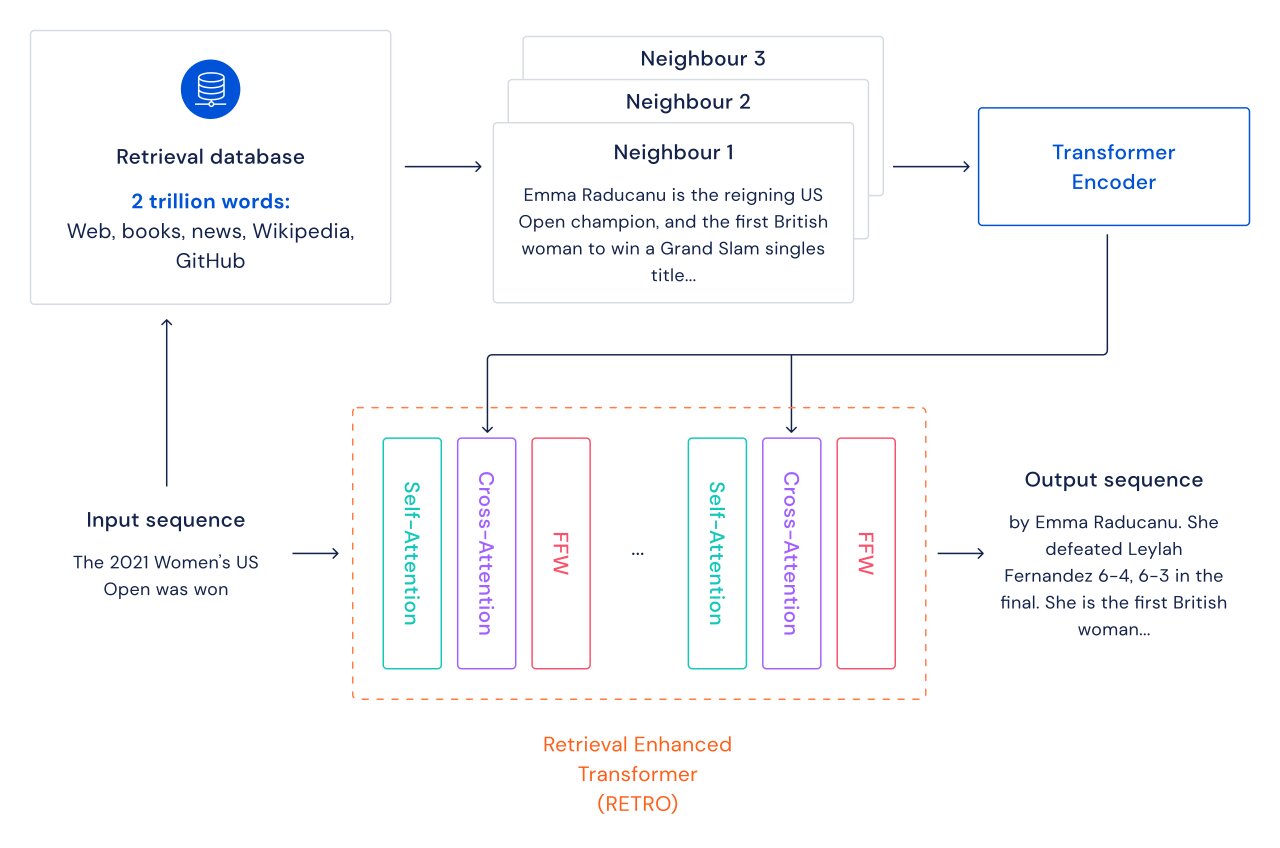
In particular, I’d recommend this article due to the provided example of Spark. This was built by the author using Chainlit, and retrieval of information about prompt engineering. I find such examples useful, especially at a time when the LLM space is growing and changing every day.
The article also does a great job of defining Retrieval Augmented Generation by breaking down what augmented generation is, and then how you can apply retrieval to that. It’s a very neat breakdown of the method into its core components.